- Forgetting diagnosis across fine-tuning depth. We reveal that MLLMs experience severe catastrophic forgetting as fine-tuning extends to earlier decoder layers, and that existing approaches are either ineffective or exhibit inconsistent behavior under this regime.
- A scalable sparse fine-tuning method. Model-Dowser introduces a data-free importance score derived from input activations and output sensitivity, selectively freezing critical parameters to enable effective downstream learning without loss of pretrained knowledge.
- Theoretical justification. We provide a theoretical analysis showing that our importance score captures the sensitivity of model outputs to individual parameter perturbations, explaining why preserving high-score parameters retains pretrained generalization.
- State-of-the-art results with practical efficiency. Experiments on LLaVA-1.5-7B and NVILA-Lite-2B across diverse downstream tasks show that Model-Dowser consistently outperforms prior methods while requiring no additional memory beyond standard fine-tuning.
Motivation
Recent work on catastrophic forgetting in MLLMs is predominantly evaluated under shallow fine-tuning settings, where only the last few layers of the language decoder are updated. However, earlier layers play a critical role in multimodal understanding, suggesting that shallow fine-tuning may not fully exploit the model's adaptation capacity.
We examine forgetting under deeper fine-tuning regimes and find that post-merging methods degrade rapidly once fine-tuning extends to earlier decoder layers. Sparse fine-tuning methods are more stable, but their memory overhead limits scalability. Model-Dowser remains robust across all fine-tuning depths while matching the memory complexity of standard fine-tuning.
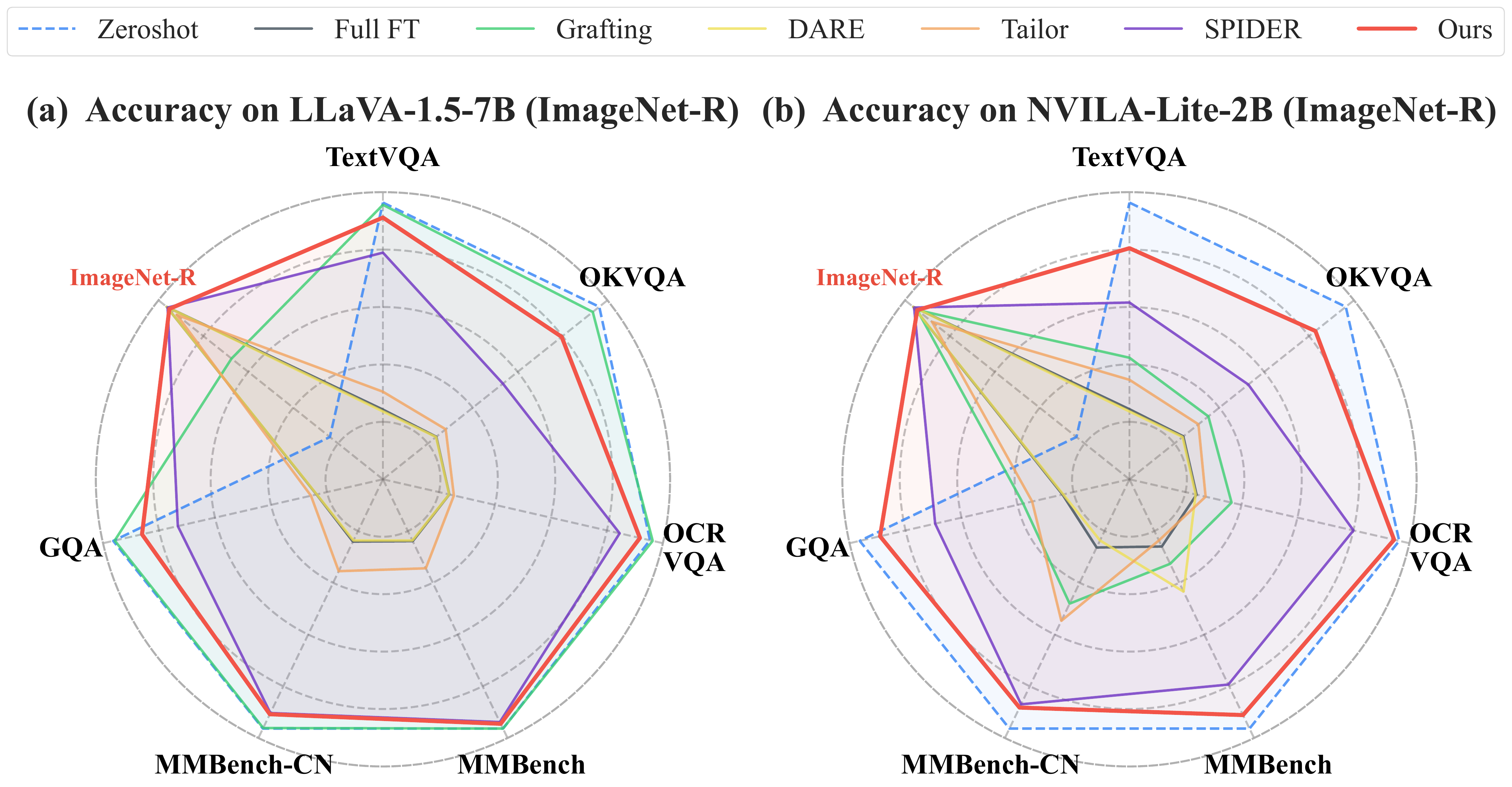
Radar charts comparing upstream and downstream task balance across methods.
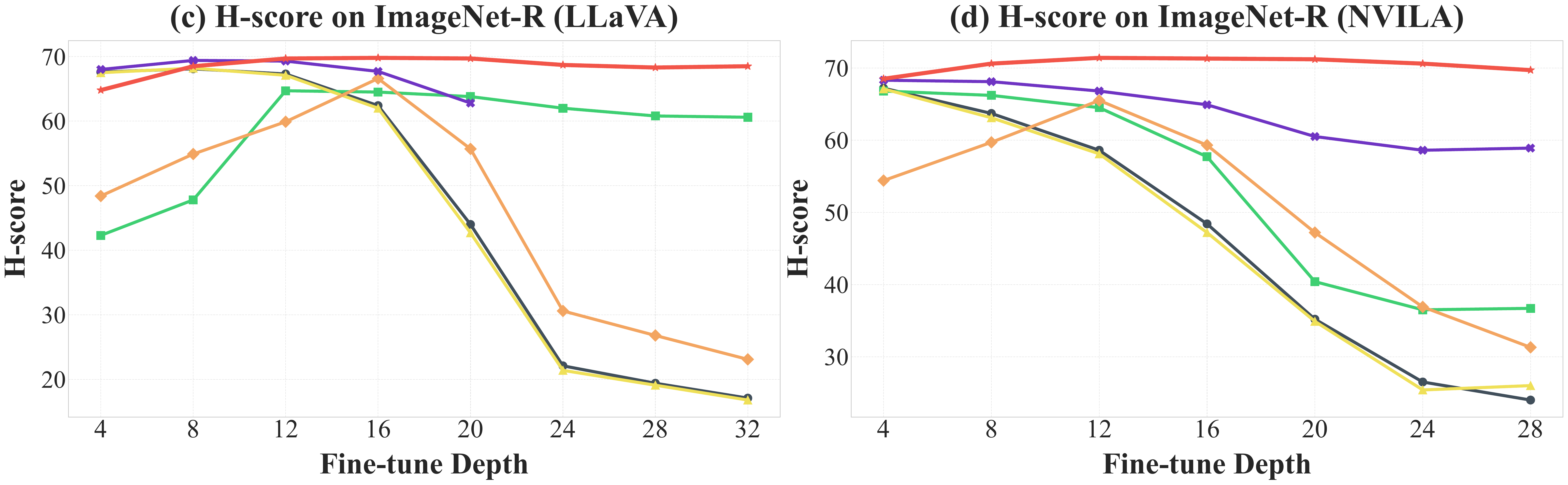
H-score stability across varying fine-tuning depths. Model-Dowser (red) consistently outperforms prior methods.
Method Overview
Model-Dowser consists of a three-stage pipeline that identifies and preserves functionally critical parameters before downstream fine-tuning:
- Probing — Sample Jacobian matrices and input activations using synthetically generated prompts. This data-free step leverages the MLLM's own generative capability to probe its functional response without requiring access to the original pretraining data.
- Compute Score — Assign a sensitivity-based importance score to each parameter: Sij = ‖Ji‖2 · |Wij| · |hj−1|, jointly capturing output sensitivity, connection strength, and input activity.
- Sparse Fine-tuning — Freeze the top-importance parameters and update only the least important ρ% during downstream adaptation, preserving pretrained knowledge while enabling task-specific learning.
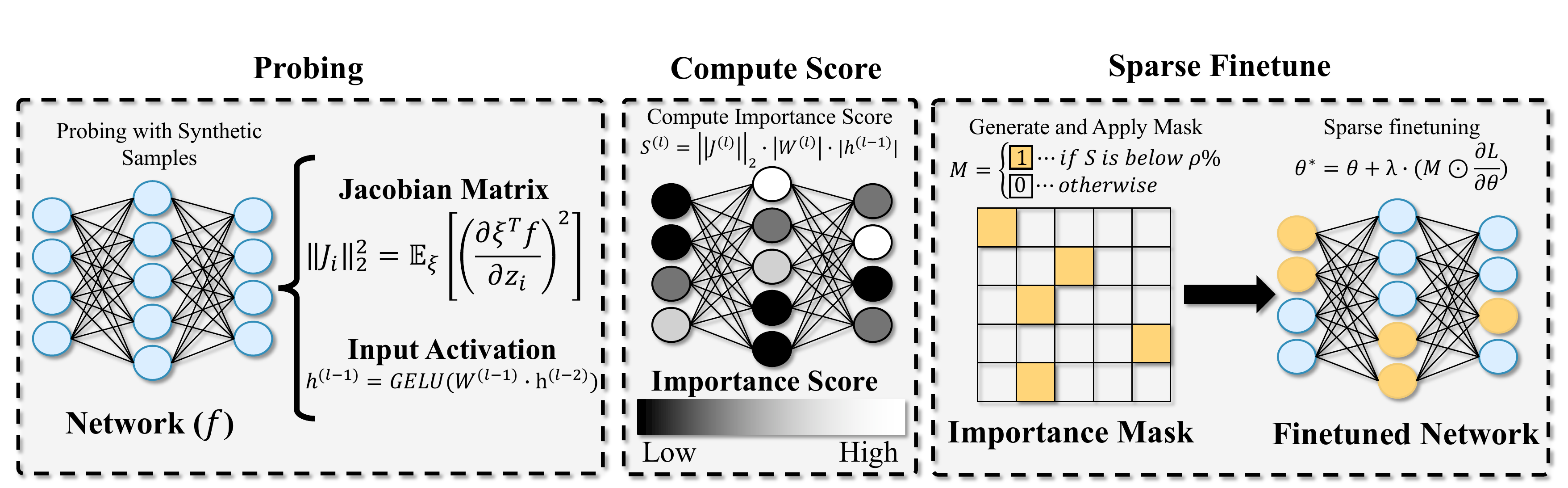
Overall architecture of Model-Dowser. Parameters highlighted in yellow are updated during sparse fine-tuning.
Key Contributions
Key Findings
1. Robust Balance Between Upstream and Downstream Performance
Across all benchmarks, different methods often achieve comparable downstream performance, but their ability to preserve pretrained knowledge varies significantly. Model-Dowser achieves the highest H-scores among all evaluated methods by preserving functionally sensitive parameters during sparse fine-tuning. For example, on NVILA-Lite-2B, Model-Dowser achieves H-scores of 85.7 and 71.2 on COCO-Caption and ImageNet-R respectively, outperforming the second-best (SPIDER) by 7.4 and 10.7 points. On LLaVA-1.5-7B, it achieves H-scores of 79.9 and 69.7 on the same tasks.
Performance comparison on NVILA-Lite-2B and LLaVA-1.5-7B across all downstream tasks
ImageNet-R
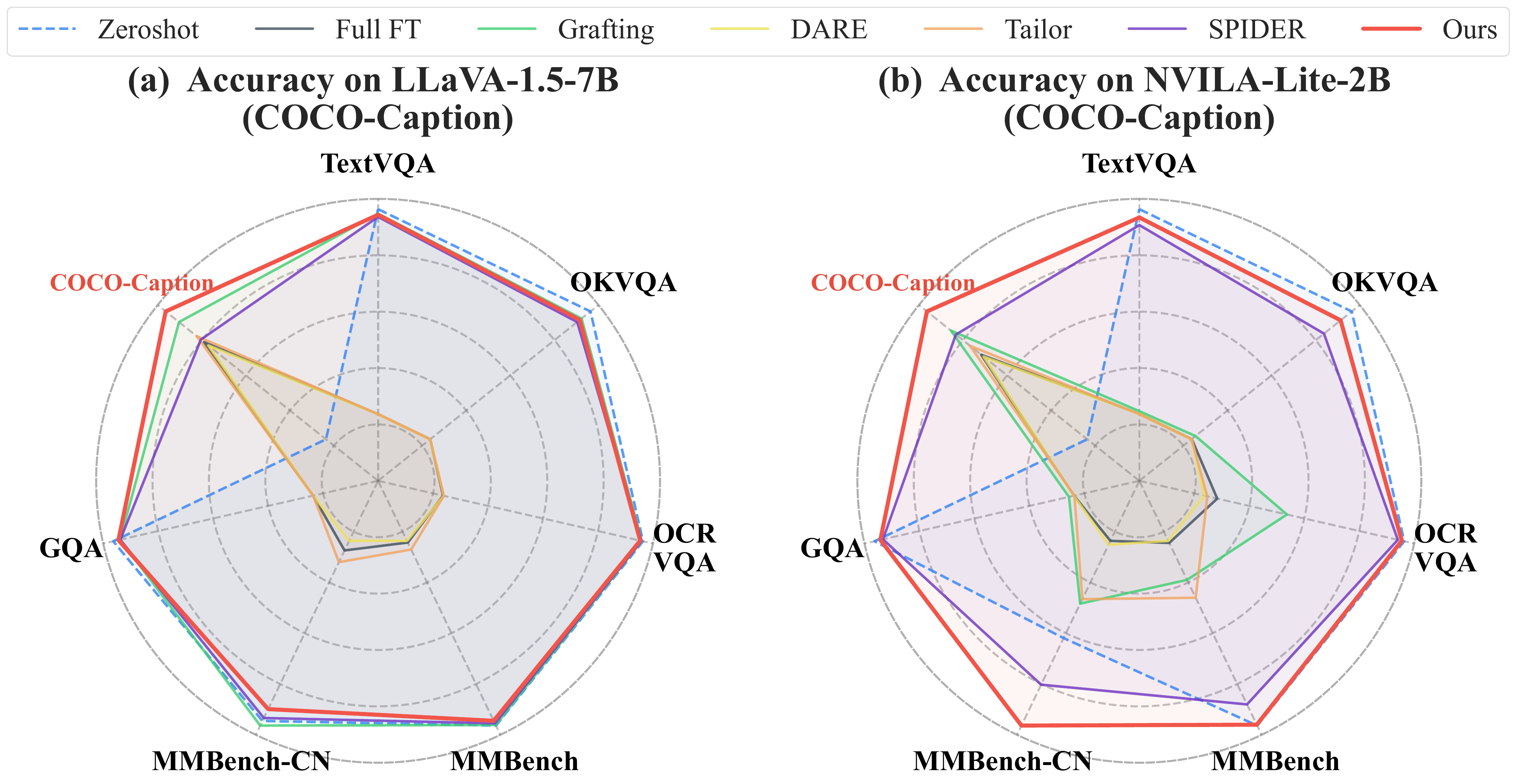
COCO-Caption
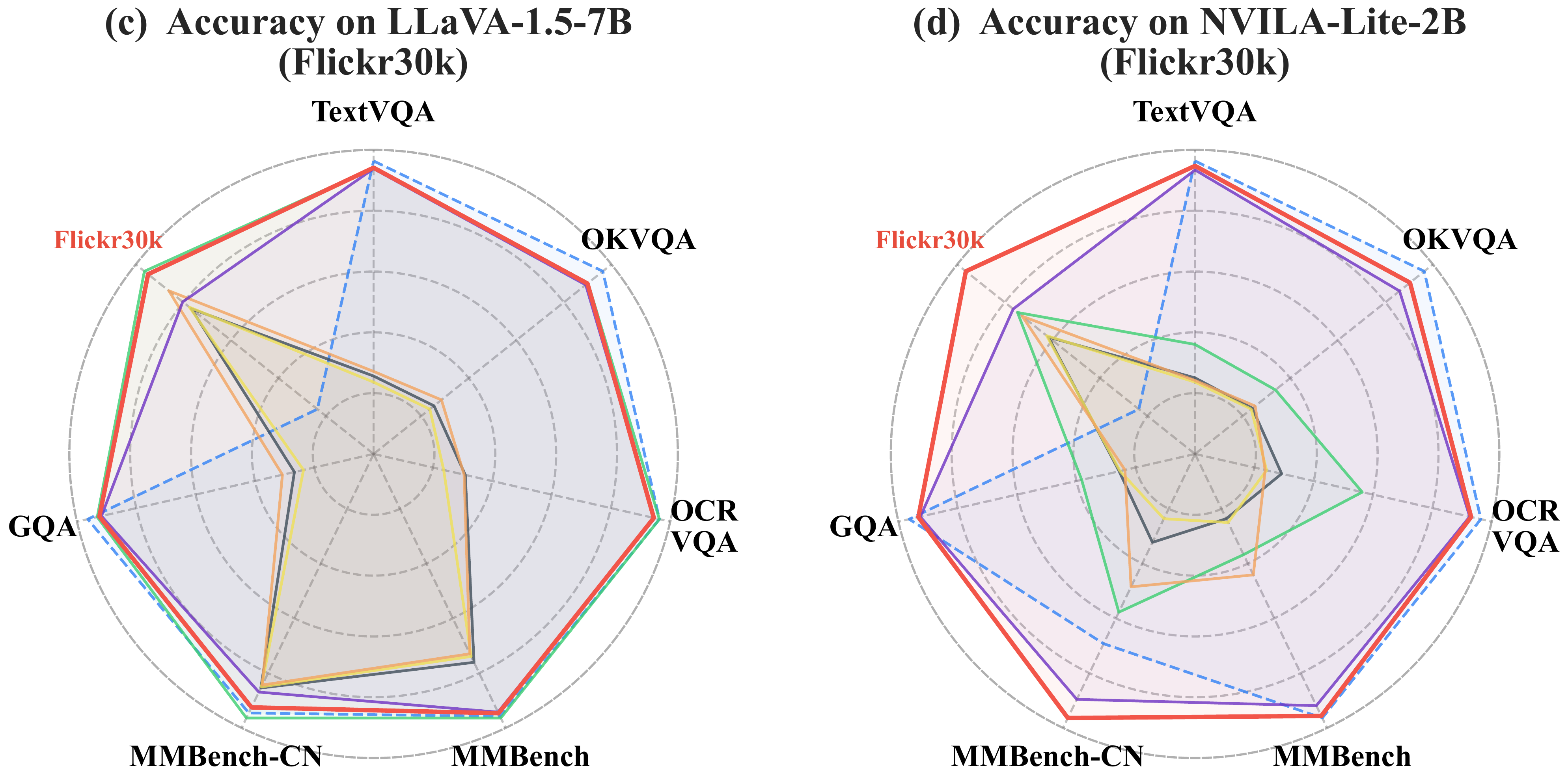
Flickr30k
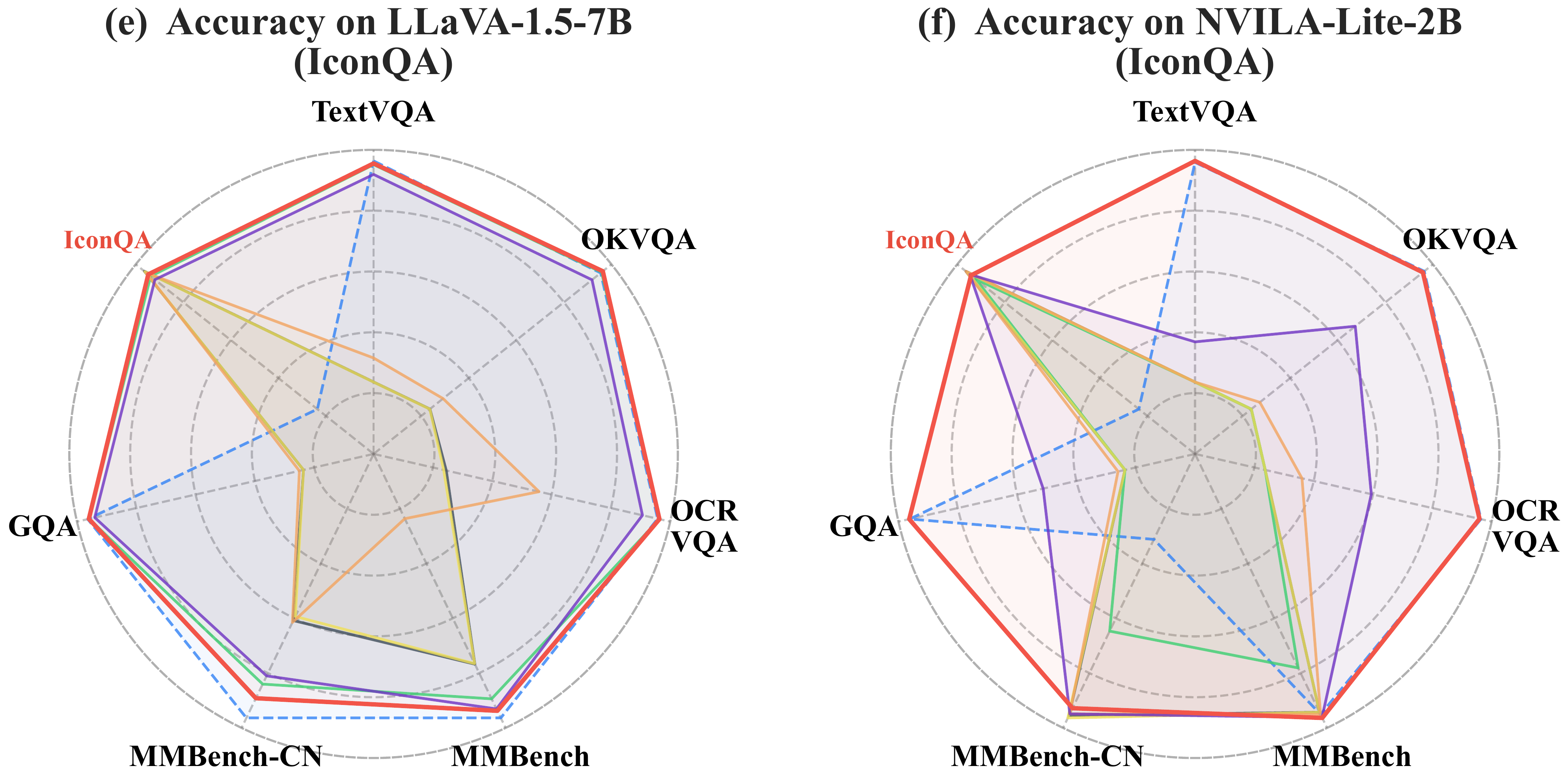
IconQA
2. Increased Vulnerability of Early Decoder Layers
Layer-wise analysis reveals that catastrophic forgetting is most severe when fine-tuning extends to early decoder layers. Post-merging methods (Grafting, DARE, Tailor) maintain stability across the last 4–16 layers but collapse when updates reach earlier layers, because post-hoc weight patching cannot recover from extensive disruption. SPIDER is more stable but still underperforms Model-Dowser across all 32 layers on LLaVA and 28 layers on NVILA. Model-Dowser preserves sensitive functional anchors across all depths, sustaining stability throughout.
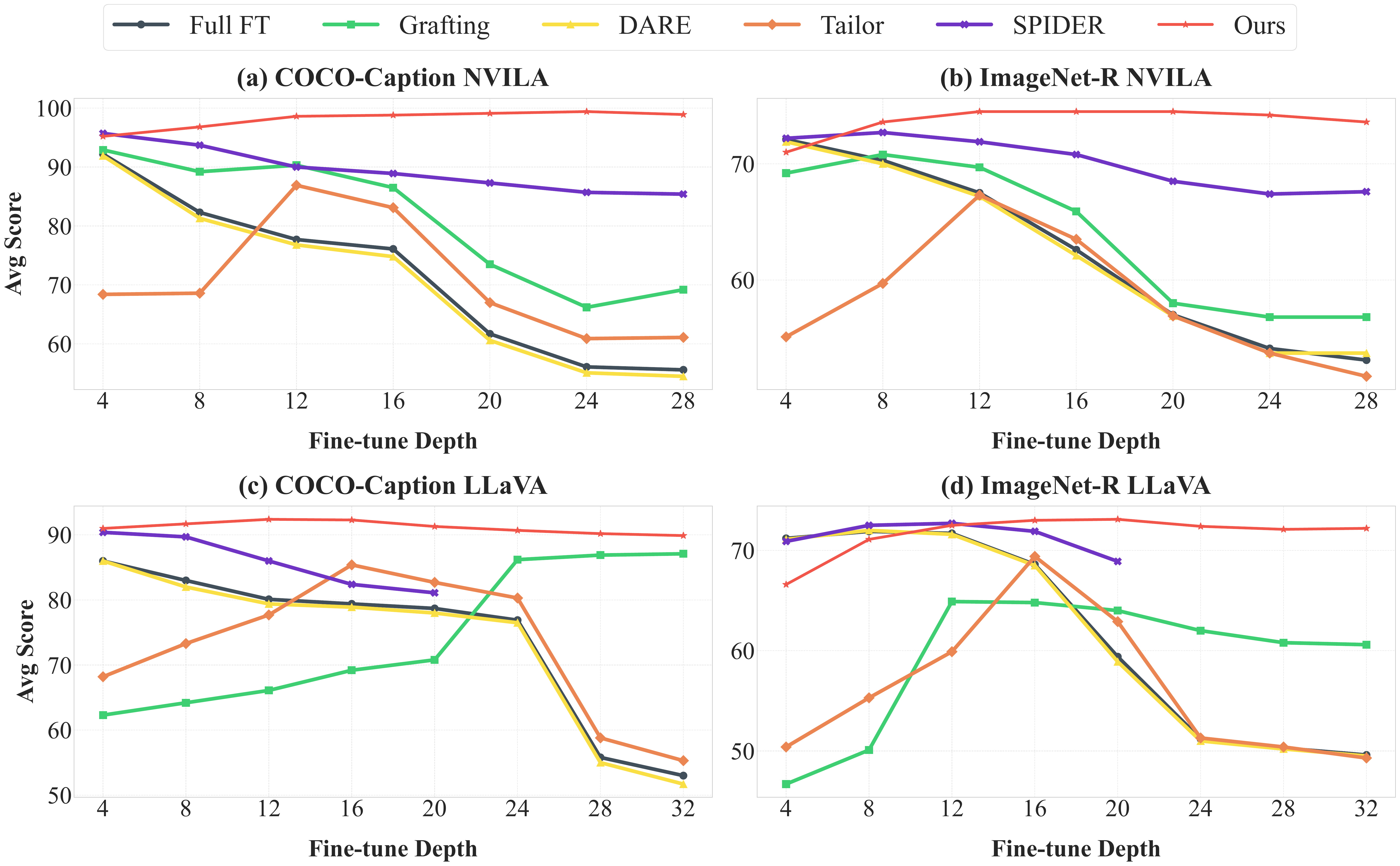
Performance across fine-tuning depths on COCO-Caption and ImageNet-R. The x-axis shows the number of fine-tuned layers, counted from the output layer toward the input layer.
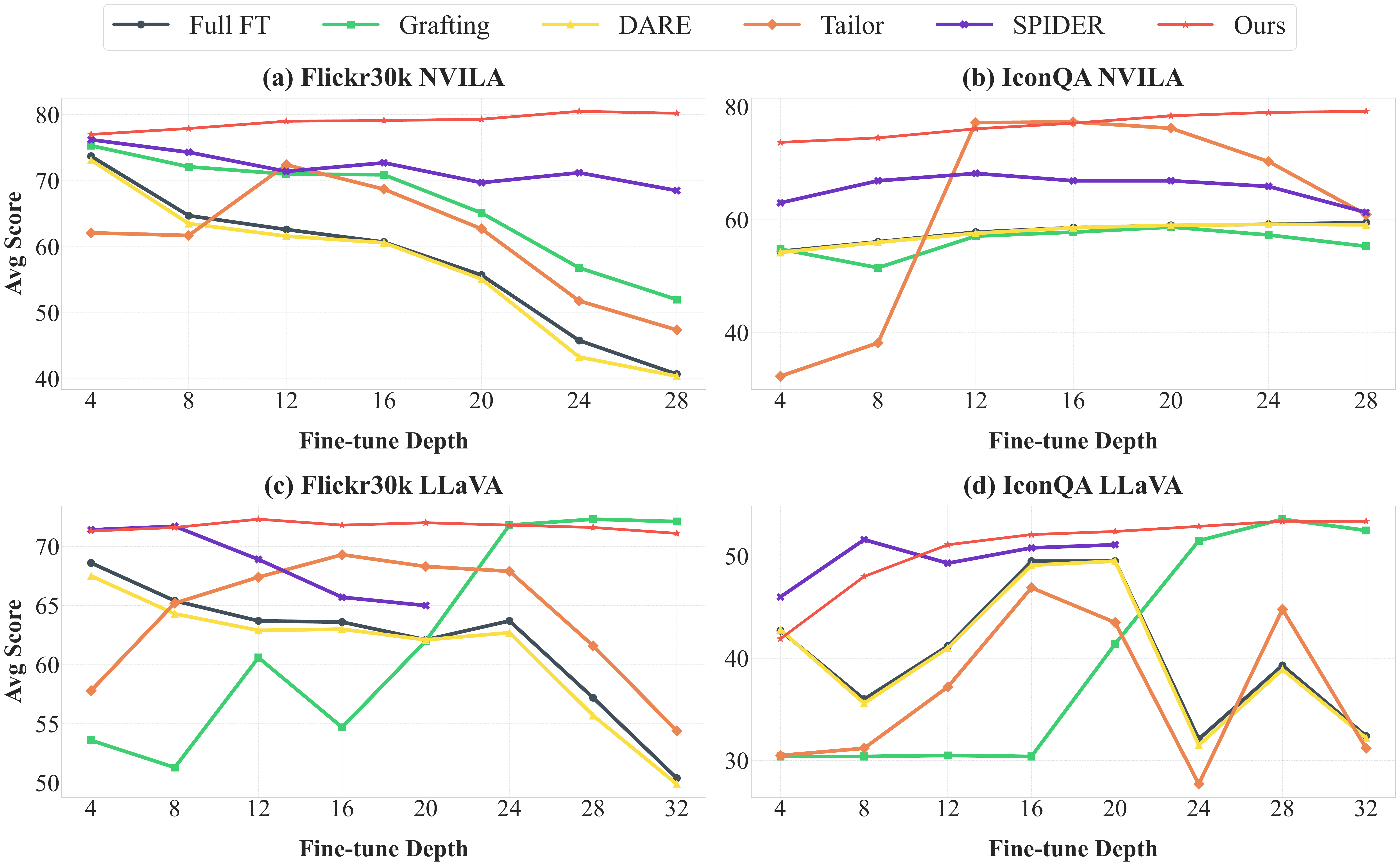
Performance across fine-tuning depths on Flickr30k and IconQA.
3. Robustness to Update Ratios
Model-Dowser maintains a wide operational window for the update ratio ρ. Average upstream performance remains stable for mask ratios up to ρ = 0.25, and consistently outperforms Full-FT (ρ = 1.0) across all settings. This demonstrates that the functional importance identified by sensitivity scoring is highly concentrated: as long as the most critical parameters are protected, the model remains robust to significant task-specific updates elsewhere.
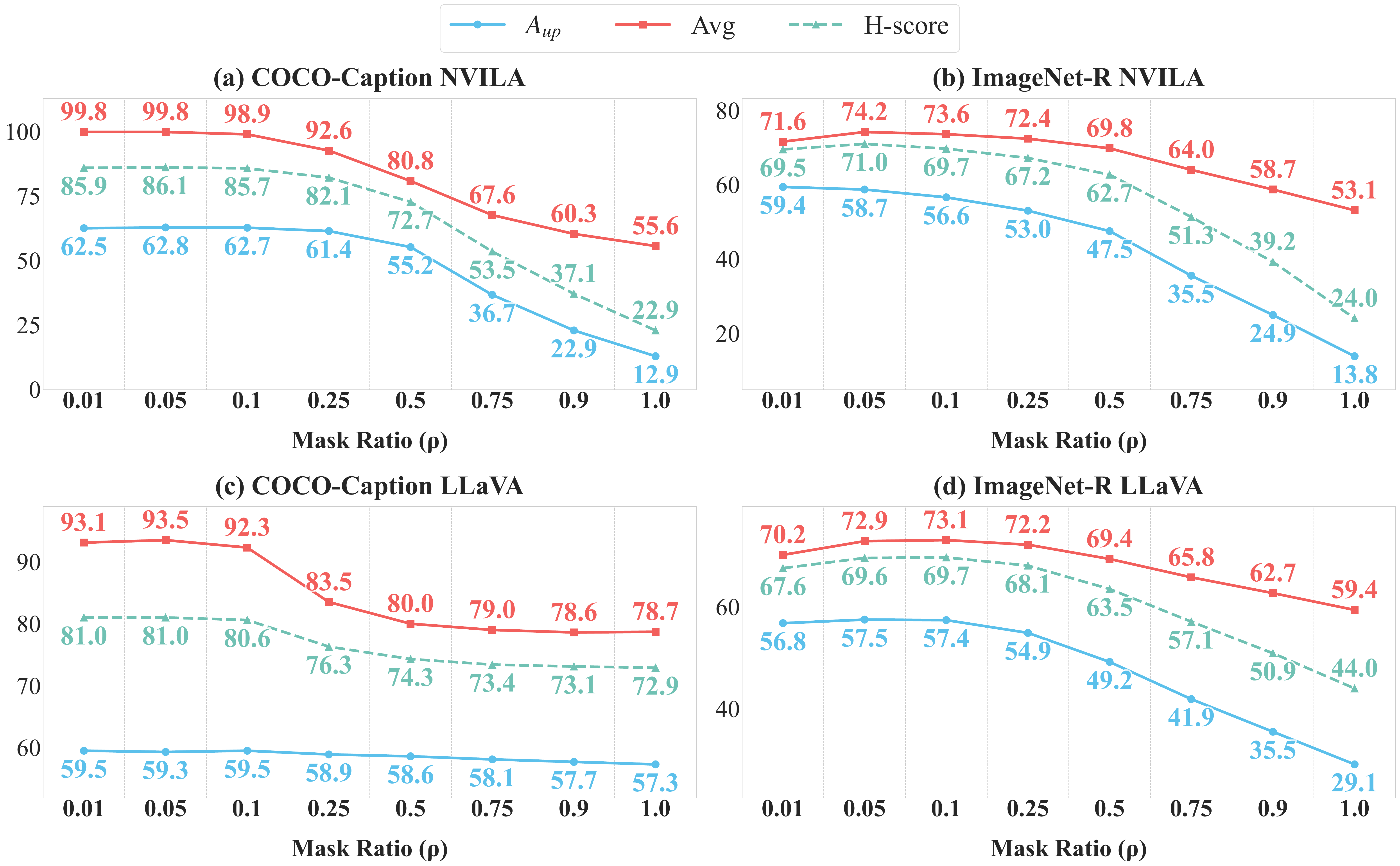
Upstream/downstream performance across update ratios (ρ) on COCO-Caption and ImageNet-R for NVILA-Lite-2B (a–b) and LLaVA-1.5-7B (c–d).
Same analysis on Flickr30k and IconQA.
4. Stability of Data-Free Importance Estimation
The data-free importance estimation yields a stable, robust ranking of parameter sensitivity. With R = 8 Rademacher vectors and N = 64 Monte Carlo samples, Model-Dowser achieves a Hamming distance of 0.050 ± 0.002 and Spearman correlation of 0.891 ± 0.003 relative to real-data scoring, while random selection shows zero correlation.
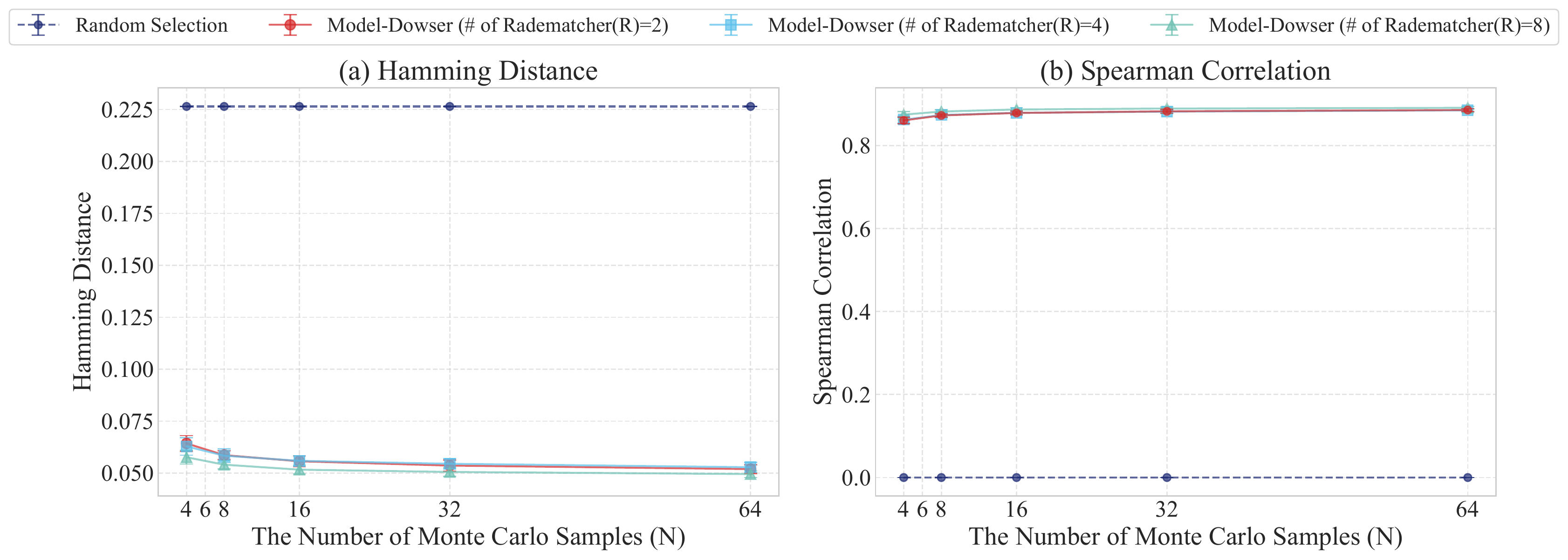
Significance analysis of the data-free importance estimation.